
近年のChatGPTやGoogle検索のAI Overviewsの普及に伴って、「RAG(検索拡張生成, Retrieval-Augmented Generation)」という言葉を耳にする機会が増えているのではないでしょうか。
RAGとは、AI(LLM)が回答を生成する前に、外部の文書やデータベースから関連する情報を検索し、その情報をもとに回答を生成する仕組みのことです。
AIをシステムに取り入れるエンジニアや、AI検索への最適化(LLMO)が必要なマーケティング担当者にとって、これから必須ともいえるAIの基礎知識と言えるでしょう。
本記事では、AI時代に必ず知っておくべきRAGの基本知識から、その成功を左右する重要なポイント、AI検索最適化(LLMO/GEO)との関係まで、わかりやすく解説します。
ぜひご一読ください。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり

現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちらシュワット株式会社のLLMO対策支援サービスをチェック
- 自社のLLMOを診断したい⇒「LLMO無料診断を依頼する」
- 専門家に伴走支援してほしい⇒「LLMOコンサルティングサービス」
- LLMOを動画で学びたい⇒「LLMOウェビナー」
RAG(検索拡張生成)とは?
RAG(ラグ)とは、大規模言語モデル(LLM)が持つ知識を、外部の情報源を用いて拡張し、より信頼性が高く、最新の情報を反映した回答を生成するための技術的な仕組みです。
「Retrieval-Augmented Generation」の略で、日本語では「検索拡張生成」と訳されます。
簡単にいうと、AIが回答を生成する際に、「カンニングペーパーを見ながらテストに答える」ような仕組みです。
詳しく見てみましょう。
RAGの基本的な仕組み
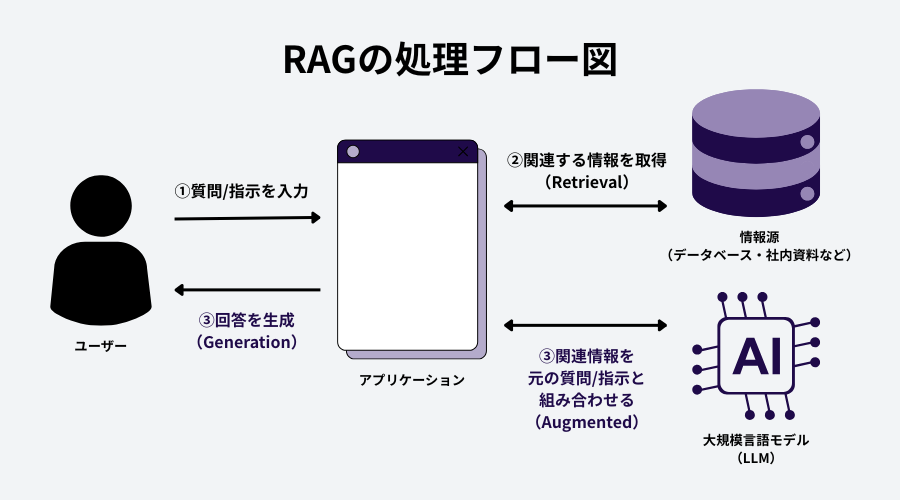
RAGの動作は、LLMが回答を「生成(Generation)」する前に、外部から情報を「検索(Retrieval)」し、その情報を利用して回答を「拡張(Augmented)」するという、名前通りのプロセスで実行されます。
- 検索 (Retrieval)
ユーザーから質問や指示(プロンプト)が入力されると、システムはまず、その質問の意図に関連する情報を、あらかじめ用意された外部の情報源(データベース、社内文書、Webサイトのインデックスなど)から検索します。このとき、単なるキーワード一致だけでなく、文脈や意味の近さで検索される「ベクトル検索」という技術も使われます。 - 拡張 (Augmented)
検索によって得られた関連情報を、ユーザーの元の質問や指示と組み合わせ、LLMへの新しい指示(プロンプト)を作成します。例えば、「(ここに検索で見つけた情報)という情報を参考にして、ユーザーの(元の質問)に答えてください」といった形にプロンプトを「拡張」します。 - 生成 (Generation)
拡張されたプロンプトを受け取ったLLMは、検索で得られた具体的な情報を「根拠」として参照しながら、最終的な回答を生成します。これにより、LLMが元々持っていない知識(最新情報や社内情報)であっても、正確に回答することが可能になります。
なぜ今RAGが注目されているのか?
RAGが急速に注目を集めている背景には、ChatGPTやGoogleのAI Overviewsといった生成AIサービスの爆発的な普及があります。
これらのサービスで使われるLLMは非常に高性能ですが、単体では以下のような課題を抱えています。
- ハルシネーション(情報の捏造)
LLMは、学習データにない情報や、曖昧な知識について質問されると、事実に基づかない「それらしい嘘」の情報を自信を持って生成してしまうことがあります。これは、LLMが確率に基づいて「次に来る可能性が最も高い単語」を予測し続けるという仕組みに起因します。実際、GoogleやNVIDIAなどの主要なAI開発企業においても、ハルシネーションをAI活用の主要な障壁として認め、その解決策としてRAGの仕組みや導入事例が紹介されています。 - 情報の最新性(ナレッジ・カットオフ)
LLMは、特定の時点までのデータで学習されているため、それ以降の最新情報(例:昨日のニュース、最新の製品情報、最新の法律)についての知識を持っていません。 - 専門性・内部情報の欠如
学習データに含まれない、特定の企業や業界の内部情報、専門的なニッチ知識には対応できません。
RAGは、これらの課題を解決する手段として登場しました。
LLM自体をゼロから再学習させる(膨大なコストと時間がかかる)のではなく、LLMにあらかじめ「検索」というカンニングペーパー(外部情報)を持たせることで、LLMが「知っていること」だけで答えさせるのではなく、「調べたこと」に基づいて答えさせることが可能になったのです。
RAGがもたらす主なメリット
RAGを導入することにより、LLMが単体で抱える課題が解決され、以下のようなメリットが生まれます。
- 回答精度の向上(ハルシネーションの抑制)
検索した具体的な情報源を「根拠」として回答を生成するため、LLMが不確かな知識で回答する(=ハルシネーション)を大幅に防ぎ、「知らない」情報については「調べた結果」に基づいて回答するため、事実に基づいた回答が期待できます。 - 情報源の明示による信頼性の確保
多くのRAGシステムでは、回答と同時に「どの情報を参照したか」という出典元(Webサイトへのリンクなど)を提示します。これにより、ユーザーは情報の真偽を自分で確認でき、回答への信頼性が高まります。 - 最新情報や独自データへの対応
LLM自体を再学習させる必要がないため、外部の情報源を更新するだけで、最新の情報や企業独自の内部データに基づいた回答が可能になります。
事実、デロイトの最近のGen AI調査によると、組織の 42% が生産性、効率性、コストの大幅な向上を実現しています。
RAGの成功を左右する重要なポイント
RAGは強力な仕組みですが、その性能を最大限に引き出すには、いくつかの重要なポイントがあります。
特にAIシステムを開発・導入するエンジニアにとって、以下の3点はRAGの品質を左右します。
- 検索(Retrieval)の質
- LLMへの情報連携(プロンプト)
- コストと速度のバランス
それぞれ詳しく見ていきましょう。
ポイント1:検索(Retrieval)の質
RAGの回答品質は、「検索の質」に大きく依存します。
LLMがどれほど優秀でも、参照する情報が不正確であったり、的外れであったりすれば、良い回答は生成できません。
- データの質と範囲
どのような外部データを参照させるかが最も重要です。信頼できる最新の情報を、適切な範囲で用意する必要があります。 - 検索クエリと検索技術
ユーザーの多様な質問(自然言語)を、どう解釈して「検索クエリ」に変換するかが重要です。近年では、従来のキーワード検索に加え、AIが単語の「意味の近さ」を理解して検索できる「ベクトル検索(セマンティック検索)」という技術が不可欠となっています。
事実、スタンフォード大学の研究によって、RAGベースのシステムでさえも17%以上の確率でハルシネーションを起こすことがあり、その原因は、LLMが「嘘をついた」からではなく、RAGの検索ステップが「間違った、あるいは不適切な根拠」をLLMに提供してしまったためとされています。
ポイント2:LLMへの情報連携(プロンプト)
検索で見つけた関連情報を、そのままLLMに渡すだけでは不十分です。
その情報をどのように「指示(プロンプト)」としてLLMに連携するかが、回答の精度を左右します。
関連性の低い情報が混入すると、かえって回答のノイズになることもあります。
「元の質問」と「検索で得た情報」を効果的に組み合わせ、「この情報に基づいて、質問に答えてください」と明確に指示するプロンプトエンジニアリングの技術が、RAGの精度に直結します。
ポイント3:コストと速度のバランス
RAGは、回答を生成するたびに「検索」というプロセスを挟むため、LLMが単体で応答するよりも時間がかかります。
また、高度なベクトル検索の実行や、LLMのAPIコール回数の増加(検索用クエリの生成、最終回答の生成など)は、そのまま運用コスト(API利用料やコンピューティングリソース)に跳ね返ります。
ユーザー体験を損なわない応答速度と、ビジネス的に許容可能な運用コストの範囲内で、いかにして回答精度を最大化するか、そのバランスを見極めることがプロジェクトの成功を左右します。
Microsoftが公開するAI開発に関するドキュメントでは「計算要件(Computational requirements)」を課題として挙げており、Oracleが公式サイトで解説するRAGとファインチューニングの比較においても「ランタイム(実行時)により多くのリソースを必要とし」、「複雑性のレイヤーを追加する」と指摘しています 。
RAGとAI検索最適化(LLMO)の関係
RAGはエンジニアだけの知識ではありません。
むしろ、これからWeb担当者やマーケティング担当者にとって、かなり重要なAIに関する基礎知識となります。
その理由は、RAGが「LLMO(AI検索最適化)」と密接に関係しているためです。
LLMO(GEO)とは何か?
LLMO(Large Language Model Optimization)とは、AI(LLM)が生成する回答において、優先的に言及・引用されるように最適化(対策)を行うことです。
これは、従来のSEO(Search Engine Optimization = 検索エンジン最適化)を拡張したような概念です。
「Generative Engine Optimization(GEO = 生成エンジン最適化)」と呼ばれることもあります。

RAGはAI検索(LLMO)にどう影響するか?
Googleの「AI Overviews」「AIモード」のようなAIが搭載された検索サービスには、RAGが用いられています。
AIはユーザーの質問に対し、Web上から関連する情報を「検索(Retrieval)」し、それを「拡張(Augmented)」して、回答を「生成(Generation)」しています。
コンテンツ制作者は、この「検索」のステップを攻略することに焦点を当てる必要があります。
従来のSEOが「検索結果の1ページ目」という限られた枠を奪い合っていたのに対して、これからのLLMOは、AIが回答を生成するために「参照する情報源」という、さらに重要なポジションを確保するための取り組みとなります。
コンテンツ制作者がRAG時代に備えるべきこと
AIがRAGの仕組みでWebを検索する以上、私たちコンテンツ制作者は、「AIに検索されやすいコンテンツ」を作る必要があります。
AIに「これは信頼できる情報源だ」と判断され、引用してもらうためには、従来のSEOで重要視されてきたE-E-A-T(経験・専門性・権威性・信頼性)に加えて、以下のような要素がさらに重要になると考えられます。
- 情報の明確さ: AIが文脈を誤解しないよう、明確かつ簡潔に記述されている。
- 構造化されたデータ: hタグやリスト、表などが適切に使われ、AIが情報の構造を理解しやすい。
- 直接的な回答の提示: ユーザーが検索しそうな質問に対して、記事の早い段階で直接的な回答を提示する。
- 独自の専門性: 他のサイトにはない、一次情報や独自の分析が含まれている。
RAGの普及は、小手先のテクニックではなく、コンテンツの「本質的な品質」がこれまで以上に問われる時代が来ることを意味しています。
RAGに関するよくある質問
ChatGPTやGoogleのAI検索とは違うものですか?
RAGは「仕組みの名前(技術)」であり、ChatGPT(の検索機能)やGoogleのAI Overviewsは「その仕組みを使ったサービス(製品)」です。
RAGは、それらのAIサービスがより正確な回答を生成するために、裏側で動いている重要な技術の一つ、と理解すると分かりやすいでしょう。
RAGにデメリットや限界はありますか?
RAGは完璧な技術ではなく、いくつかのデメリットや限界があります。
- 情報源の質への依存:検索する情報源(外部データ)の質が低いと、AIの回答の質も必然的に低くなります。
- 応答速度の低下:回答のたびに「検索」プロセスが入るため、LLMが単体で応答するより時間がかかる場合があります。
- 導入コスト:高度な検索システムを構築・維持するには、開発コストや運用コストがかかります。
RAGという言葉はいつ誕生しましたか?
「RAG」という用語は、2020年にFacebook AI Research(現Meta AI)の研究者らによって発表され、同年の主要なAIカンファレンスであるNeurIPSで採択された論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 」によって初めて学術的に定義されました。
RAGと「ファインチューニング」はどう違いますか?
どちらもLLMの性能を向上させる技術ですが、目的とアプローチが異なります。
これらは排他的なものではなく、「ファインチューニングで口調を整え、RAGで最新情報を回答させる」といったように、両方を組み合わせて使うこともあります。
- RAG: LLM自体は変更せず、「外部から情報を検索して利用する」技術です。知識の「更新性」や「正確性」を高めるのに適しています。(例:最新のニュースを答えさせる)
- ファインチューニング: LLM自体に「追加学習をさせて調整する」技術です。LLMの「口調」や「特定のタスクへの専門的な振る舞い」を獲得させるのに適しています。(例:カスタマーサポート用の丁寧な口調を覚えさせる)
| 項目 | RAG(検索拡張生成) | ファインチューニング |
|---|---|---|
| アプローチ | LLM自体は変更せず、「外部」から情報をカンニングペーパーのように検索して利用します。 | LLM自体に「内部」の知識として追加学習をさせ、モデルの振る舞いや口調を「調整」します。 |
| 目的 | 「知識の提供」に特化しています。最新情報への対応、社内文書の参照、ハルシネーションの抑制など、LLMが「知らないこと」を答えさせるのに適しています。 | 「振る舞いの学習」に特化しています。特定のスタイル、口調、専門用語の使い方、特定のタスクの実行方法をLLMに「覚えさせる」のに適しています。 |
| 例 | 最新の株価やニュースを答えさせる、社内規定に基づいて回答する。 | カスタマーサポート用の丁寧な口調を覚えさせる、特定のフォーマットでコードを生成させる。 |
RAGの登場で、SEOは不要になりますか?
不要にはなりません。むしろ、その重要性が形を変えて高まると考えられます。
これからのSEO(あるいはLLMO)は、検索順位を上げるだけでなく、RAGの「検索」ステップにおいて「AIから参照される高品質な情報源」となるための取り組みが中心になっていくでしょう。
RAGを導入・実装するにはどうすればよいですか?
RAGを実装するには、主に2つの方法があります。
一つは、AWS(Amazon Bedrock)、Google Cloud(Vertex AI Search)、Microsoft(Azure AI Search)などが提供する、RAGの仕組みが組み込まれたマネージドサービス(PaaS)を利用する方法です。これにより、インフラの管理コストを大幅に削減できます。
もう一つは、「LangChain」や「LlamaIndex」といったオープンソースのフレームワークを活用し、自前でシステムを構築する方法です。こちらは自由度が高い反面、ベクトルデータベースの選定やパイプラインの構築など、高度な設計・実装スキルが求められます。
まとめ
本記事では、AI時代の必須知識である「RAG(検索拡張生成)」について、その基本から成功のポイント、そしてLLMOとの関係性までを解説しました。
RAGは、LLMの「ハルシネーション」や「情報の最新性」といった課題を解決し、AIの回答精度を飛躍的に向上させる仕組みです。
この技術は、AIを開発するエンジニアだけでなく、RAGによって情報を参照される側となるコンテンツ制作者にとっても、今後の戦略を左右する重要な概念となります。
AIが信頼できる情報源としてあなたのコンテンツを選んでくれるよう、RAGの仕組みを理解し、本質的なコンテンツの価値を高めていくことが、これからのAI時代を勝ち抜く鍵となるでしょう。
- 独自開発のLLMO分析ツールを活用
- 国内他社にはできない詳細なAI可視性(どれだけAIに言及・推奨・引用されているか)分析が可能
- 現状のLLMO対策の課題と、優先的に取り組むべき施策がまるわかり
現在、AI検索時代への対応やLLMO対策について、お考えでしたらぜひ弊社のLLMO無料診断をご活用ください。独自開発のLLMO分析ツールを活用し詳細な分析を実施。国内企業では現状不可能な高度なAI可視性分析が可能です。主要なAI(ChatGPT, Google Ai Overviews等)における競合比較や現状のLLMO対策の課題と、優先的に取り組むべき施策の可視化をいたします。ぜひ下記よりお気軽にお問い合わせください。
お問い合わせはこちらシュワット株式会社のLLMO対策支援サービスをチェック
- 自社のLLMOを診断したい⇒「LLMO無料診断を依頼する」
- 専門家に伴走支援してほしい⇒「LLMOコンサルティングサービス」
- LLMOを動画で学びたい⇒「LLMOウェビナー」







